Summary
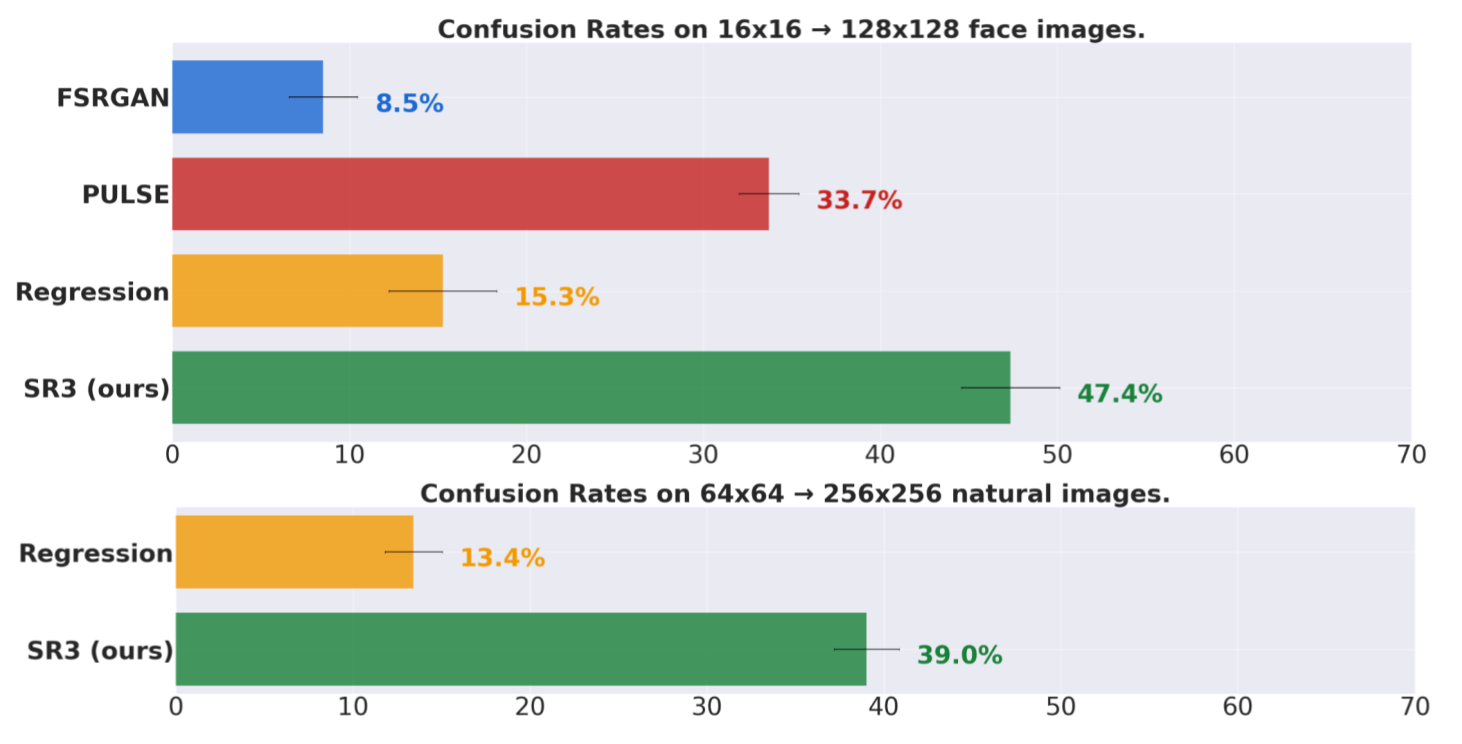
We present SR3, an approach to image Super-Resolution via Repeated Refinement. SR3 adapts denoising diffusion probabilistic models to conditional image generation and performs super-resolution through a stochastic denoising process. Inference starts with pure Gaussian noise and iteratively refines the noisy output using a U-Net model trained on denoising at various noise levels. SR3 exhibits strong performance on super-resolution tasks at different magnification factors, on faces and natural images. We conduct human evaluation on a standard 8× face super-resolution task on CelebA-HQ, comparing with SOTA GAN methods. SR3 achieves a confusion rate close to 50%, suggesting photo-realistic outputs, while GANs do not exceed a confusion rate of 34%. We further show the effectiveness of SR3 in cascaded image generation, where generative models are chained with super-resolution models, yielding a competitive FID score of 11.3 on ImageNet.
Super-Resolution Results
We demonstrate the performance of SR3 on the tasks of face and natural image super-resolution. We perform face super-resolution at 16×16 → 128×128 and 64×64 → 512×512. We also train face super-resolution model for 64×64 → 256×256 and 256×256 → 1024×1024 effectively allowing us to do 16× super-resolution through cascading. We also explore 64×64 → 256×256 super-resolution on natural images.

Unconditional Generation Results
We generate unconditional 1024×1024 unconditional face images using a cascade of an unconditional diffusion model at 64×64 resolution followed by two 4× super-resolution models. We also generate 256×256 class conditional natural images by using a cascade of a class conditional diffusion model at 64×64 resolution followed by a 4x super-resolution model. Cascaded generation allows training different models in parallel and inference is also efficient as lower resolution models can use more iterations, while higher resolution models use fewer iterations.



Related projects
Citation
For more details and additional results, read the full paper.
@article{saharia2021image,
title={Image super-resolution via iterative refinement},
author={Saharia, Chitwan and Ho, Jonathan and Chan, William and Salimans, Tim and Fleet, David J and Norouzi, Mohammad},
journal={arXiv:2104.07636},
year={2021}}
}